☁️AWS Machine Learning Blog•Stalecollected in 30m
AWS HyperPod Slashes Seismic Training to 5 Days
#distributed-training#seismic-models#context-windowsamazon-sagemaker-hyperpodawssagemaker-hyperpodtgs
💡36x faster training for foundation models on AWS – ideal for scaling seismic AI workloads
⚡ 30-Second TL;DR
What Changed
Achieved near-linear scaling for distributed training
Why It Matters
This breakthrough enables faster development of geophysical AI models, democratizing large-scale seismic analysis for energy and research sectors. AWS practitioners can now train massive models efficiently without custom infrastructure.
What To Do Next
Test SageMaker HyperPod clusters for your large ViT model training to verify scaling efficiency.
Who should care:Developers & AI Engineers
Key Points
- •Achieved near-linear scaling for distributed training
- •Cut training time from 6 months to 5 days
- •Expanded context windows for larger seismic volumes
- •Used Vision Transformer-based Seismic Foundation Models (SFM)
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
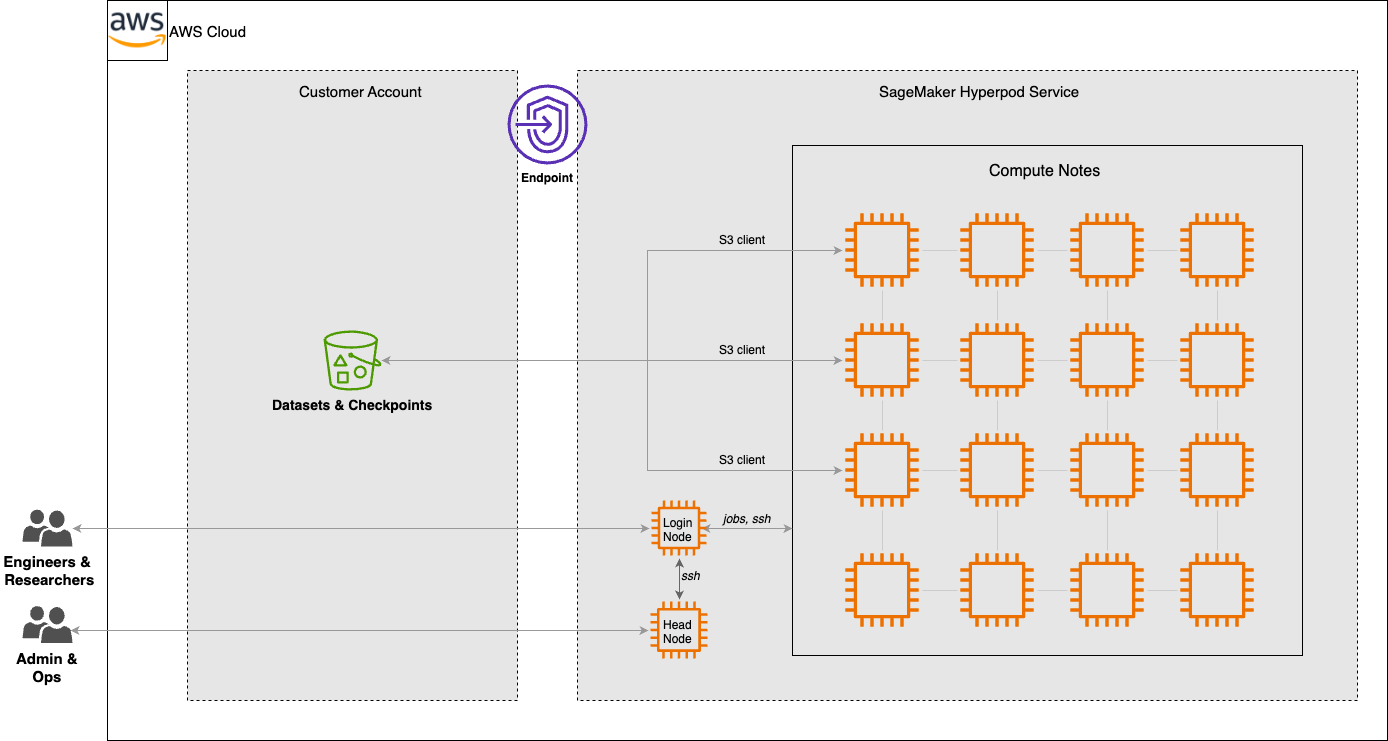
- •TGS utilized a distributed training strategy on SageMaker HyperPod that specifically optimized the orchestration of thousands of GPU instances, minimizing the overhead typically associated with checkpointing and synchronization in large-scale model training.
- •The Seismic Foundation Model (SFM) architecture leverages a masked autoencoder approach, allowing the model to learn representations from vast, unlabeled seismic datasets, which is critical for subsurface imaging where labeled data is scarce.
- •The reduction in training time was facilitated by the integration of AWS's custom-built EFA (Elastic Fabric Adapter) networking, which provides the low-latency, high-bandwidth interconnects necessary for the near-linear scaling observed during the training of the Vision Transformer.
📊 Competitor Analysis▸ Show
| Feature | AWS SageMaker HyperPod | Google Cloud Vertex AI (TPU/GPU) | Azure Machine Learning (ND-series) |
|---|---|---|---|
| Orchestration | Managed Kubernetes/Slurm-like | Managed GKE/Vertex AI | Managed Azure Kubernetes Service |
| Interconnect | EFA (up to 3200 Gbps) | Jupiter/ICI (custom) | InfiniBand (up to 3200 Gbps) |
| Scaling | Near-linear for massive clusters | Optimized for TPU pods | Optimized for InfiniBand clusters |
| Target | Large-scale LLM/Foundation models | Large-scale LLM/Foundation models | Large-scale LLM/Foundation models |
🛠️ Technical Deep Dive
- Model Architecture: Vision Transformer (ViT) adapted for 3D seismic volumes, utilizing masked autoencoder (MAE) pre-training objectives.
- Infrastructure: Deployment on Amazon EC2 P5 instances powered by NVIDIA H100 Tensor Core GPUs.
- Networking: Utilization of Elastic Fabric Adapter (EFA) with NVIDIA Collective Communications Library (NCCL) for high-performance inter-node communication.
- Data Handling: Integration with Amazon FSx for Lustre to provide high-throughput, low-latency storage for massive seismic datasets during training iterations.
🔮 Future ImplicationsAI analysis grounded in cited sources
Seismic exploration costs will decrease by at least 30% over the next 24 months.
The drastic reduction in model training time allows for more frequent iterations and higher-fidelity subsurface imaging, reducing the risk of dry holes in drilling operations.
Foundation models will become the standard for seismic interpretation by 2027.
The ability to train on massive, unlabeled datasets using foundation model architectures outperforms traditional, smaller-scale supervised learning models in generalization across diverse geological basins.
⏳ Timeline
2023-11
AWS announces SageMaker HyperPod to simplify distributed training for foundation models.
2024-05
TGS begins migration of seismic data processing workflows to AWS cloud infrastructure.
2025-09
TGS initiates the development of the Seismic Foundation Model (SFM) using Vision Transformer architectures.
2026-03
TGS achieves the 5-day training milestone for the SFM using SageMaker HyperPod.
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗