Amazon's AI Agent Eval Framework
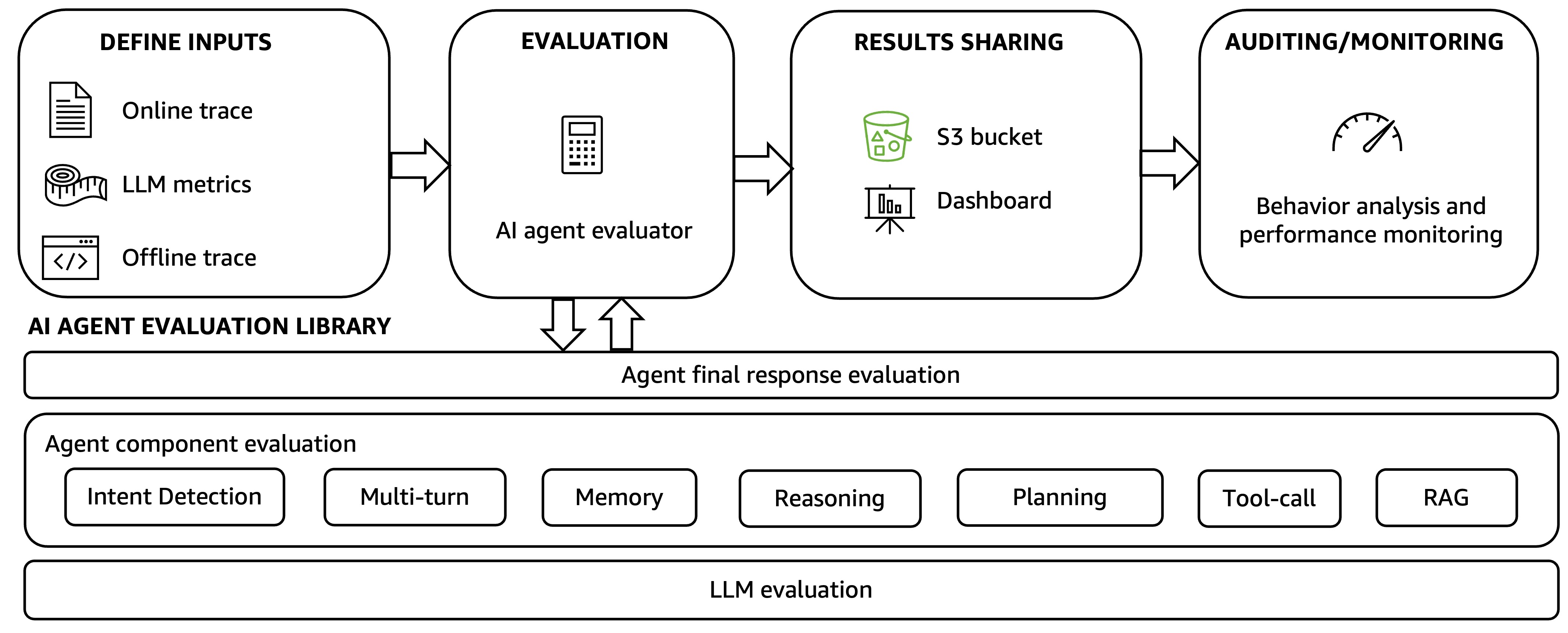
💡Amazon's real-world framework to reliably eval production AI agents at scale.
⚡ 30-Second TL;DR
What Changed
Comprehensive framework for evaluating complex agentic AI at Amazon
Why It Matters
This framework standardizes agent evaluations, improving reliability for production deployments. It offers practical insights from Amazon's scale, benefiting builders scaling agentic systems.
What To Do Next
Integrate Bedrock AgentCore Evaluations library into your agent testing pipeline via AWS ML Blog.
🧠 Deep Insight
Web-grounded analysis with 9 cited sources.
🔑 Enhanced Key Takeaways
- •Amazon's agentic AI evaluation framework addresses the complexity of multi-agent systems through automated workflows and standardized assessment procedures across diverse agent implementations[2]
- •The framework employs a four-step automated evaluation workflow: defining inputs from agent execution traces, processing through evaluation dimensions, analyzing results through performance auditing, and implementing HITL mechanisms for human oversight[2]
- •Organizations using systematic evaluation frameworks achieve nearly six times higher production success rates, with enterprises investing in unified AI governance putting significantly more AI projects into production[6]
- •Production-grade AI agents require domain-specific metrics, real-time monitoring, and consistent governance across data, models, and applications to move from impressive demos to dependable enterprise systems[6]
- •Amazon's multi-agent content review workflow demonstrates practical application through sequential extraction, verification, and recommendation stages, with modularity enabling expansion for increasingly complex content challenges[3]
📊 Competitor Analysis▸ Show
| Capability | Amazon Bedrock AgentCore | Databricks MLflow | Promptfoo | Notes |
|---|---|---|---|---|
| Evaluation Modes | On-demand + Online (production monitoring) | Experiment tracking + Model versioning | Open-source framework | Amazon offers dual-mode; Databricks emphasizes MLOps integration |
| Metrics Support | Built-in (helpfulness, harmfulness, accuracy) + Custom evaluators | Native evaluation tooling for accuracy, safety, business metrics | Judge models (Claude, Nova) | All support custom domain-specific metrics |
| Multi-Agent Support | AgentCore with planning/communication/collaboration scores | Agent Framework with native tooling | Limited multi-agent focus | Amazon explicitly addresses multi-agent complexity |
| Cost Efficiency | Integrated with Bedrock | MLflow-native | Claims up to 98% vs. human evaluation | Promptfoo highlights cost savings; Amazon integrates with broader ecosystem |
| Integration | OpenTelemetry, OpenInference, Strands, LangGraph | Native Databricks ecosystem | Framework-agnostic | Amazon emphasizes broad framework compatibility |
🛠️ Technical Deep Dive
• Evaluation Architecture: Four-layer system consisting of trace collection (offline/online), unified API access point, metric calculation, and performance auditing with automated degradation alerts[2] • Golden Dataset Methodology: Curated datasets of 300+ representative queries with expected outputs, continuously enriched with validated actual user queries to achieve comprehensive coverage of real-world use cases and edge cases[1] • LLM-as-Judge Pattern: Evaluator component compares agent-generated outputs against golden datasets using LLM judges, generating core accuracy metrics while capturing latency and performance data for debugging[1] • Domain Categorization: Queries categorized using generative AI domain summarization combined with human-defined regular expressions, enabling nuanced category-based evaluation with 95% Wilson score interval confidence visualization[1] • Multi-Agent Metrics: Planning score (successful subtask assignment), communication score (interagent messaging), and collaboration success rate (percentage of successful sub-task completion) with HITL critical for capturing emergent behaviors[2] • Content Verification Pipeline: Specialized agents for extraction (structured output by type/location/time-sensitivity), verification (criteria-driven evaluation against authoritative sources), and recommendation (actionable updates maintaining original style)[3] • Instrumentation: Automatic trace capture via OpenTelemetry and OpenInference, converted to unified format for LLM-as-Judge scoring with support for Strands, LangGraph, and other frameworks[5]
🔮 Future ImplicationsAI analysis grounded in cited sources
Amazon's comprehensive evaluation framework signals an industry inflection point where agentic AI transitions from experimental demos to production-grade enterprise systems. The emphasis on systematic evaluation and governance directly correlates with deployment success—organizations using these frameworks achieve six times higher production success rates[6]. This establishes evaluation as a continuous, non-negotiable practice rather than an afterthought, likely driving adoption of similar frameworks across enterprises. The multi-agent architecture and HITL mechanisms acknowledge emerging complexity and emergent behaviors that purely automated systems cannot capture, suggesting future agentic systems will require hybrid human-AI oversight models. Amazon's integration with Bedrock positions it as a foundational platform for enterprise agentic AI, potentially influencing industry standards for evaluation methodologies and governance practices. The focus on domain-specific metrics over generic benchmarks indicates enterprises will increasingly demand customized evaluation approaches tailored to business outcomes rather than academic metrics.
⏳ Timeline
📎 Sources (9)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
- aws.amazon.com — Build Reliable Agentic AI Solution with Amazon Bedrock Learn From Pushpays Journey on Genai Evaluation
- aws.amazon.com — Evaluating AI Agents Real World Lessons From Building Agentic Systems at Amazon
- quantumzeitgeist.com — Amazon AI Agents Content Review
- tutorialsdojo.com — Amazon Bedrock Promptfoo Rethinking LLM Evaluation Methods
- aws.amazon.com — AI Agents in Enterprises Best Practices with Amazon Bedrock Agentcore
- lovelytics.com — State of AI Agents 2026 Lessons on Governance Evaluation and Scale
- uxtigers.com — Ux Roundup 20260119
- aws.amazon.com — Build AI Agents with Amazon Bedrock Agentcore Using Aws Cloudformation
- amazon.science — Trusted AI Symposium 2026
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates


AI-curated news aggregator. All content rights belong to original publishers.
Original source: AWS Machine Learning Blog ↗