💰钛媒体•Recentcollected in 6h
AI startups face bankruptcy from high usage costs
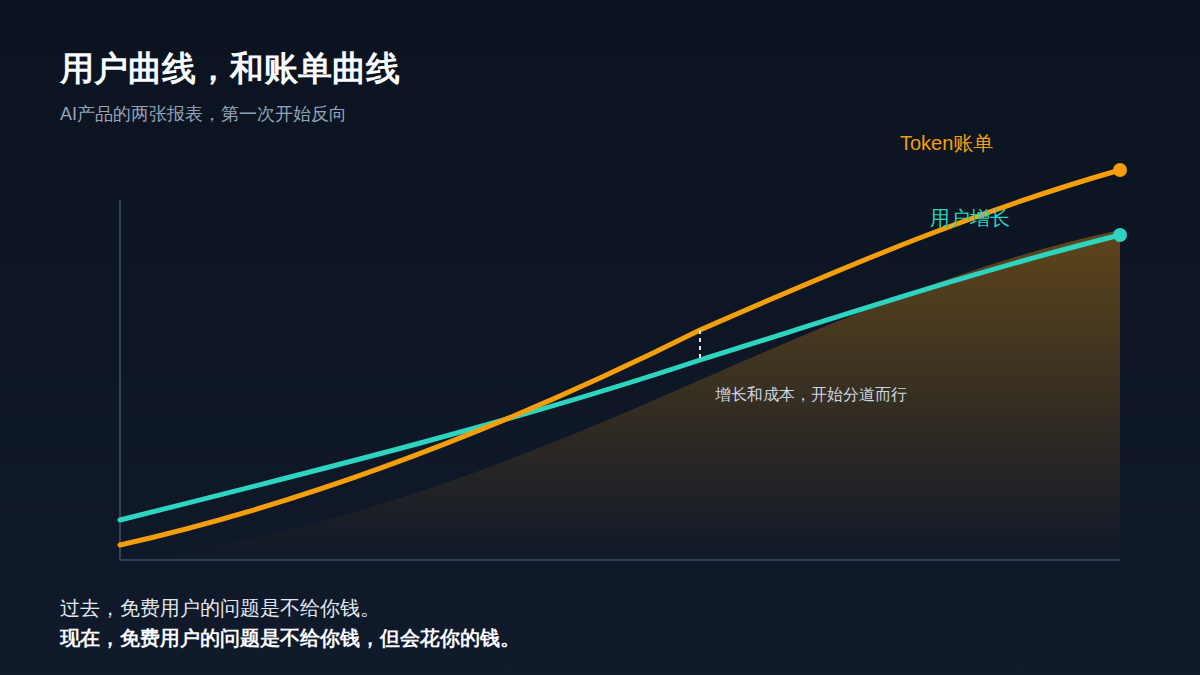
💡A critical look at why scaling AI apps can lead to bankruptcy if unit economics aren't managed.
⚡ 30-Second TL;DR
What Changed
High API and compute costs are threatening startup viability.
Why It Matters
This highlights a critical 'unit economics' crisis in the AI industry. Founders must prioritize cost-efficient inference and tiered pricing to survive.
What To Do Next
Implement strict usage quotas or move to smaller, specialized models to optimize your unit economics.
Who should care:Founders & Product Leaders
🧠 Deep Insight
AI-generated analysis for this event.
🔑 Enhanced Key Takeaways
- •The 'inference-to-revenue' gap is widening as model complexity increases, with many startups spending over 60% of their gross revenue on cloud GPU rental and API inference fees.
- •Venture capital firms are shifting investment criteria, now prioritizing 'compute-efficient' architectures and proprietary data moats over raw user acquisition metrics.
- •Startups are increasingly adopting 'model distillation' techniques, where they train smaller, specialized models on outputs from larger frontier models to slash operational costs.
- •The rise of 'inference-optimized' hardware and specialized cloud providers (GPU clouds) is creating a secondary market that challenges the dominance of hyperscalers like AWS and Azure.
- •Regulatory pressures regarding data privacy and sovereignty are forcing startups to move away from public API reliance toward on-premise or private cloud deployments, further complicating cost structures.
🛠️ Technical Deep Dive
- Model Distillation: The process of transferring knowledge from a large teacher model (e.g., GPT-4 class) to a smaller student model to reduce latency and inference costs.
- Quantization: Reducing the precision of model weights (e.g., from FP16 to INT8 or INT4) to decrease memory footprint and increase throughput on consumer-grade hardware.
- Mixture of Experts (MoE): Architectural approach where only a subset of model parameters are activated per token, significantly lowering compute requirements per inference request.
- Speculative Decoding: A technique that uses a smaller, faster model to draft tokens, which are then verified in parallel by a larger model, improving speed and reducing cost-per-token.
🔮 Future ImplicationsAI analysis grounded in cited sources
Consolidation of the AI startup ecosystem
Startups unable to achieve unit economics profitability will be forced into M&A deals by larger tech incumbents seeking talent and IP.
Shift toward edge AI deployment
To bypass high cloud inference costs, developers will increasingly optimize models to run locally on user devices, shifting the compute burden away from the startup.
⏳ Timeline
2023-03
GPT-4 API launch sets high industry standard for inference pricing
2024-05
Industry-wide GPU shortage peaks, driving up cloud compute costs for startups
2025-02
Rise of 'Small Language Models' (SLMs) as a cost-saving alternative to frontier models
2026-01
VC funding for AI startups pivots toward profitability and unit economics
📰
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: 钛媒体 ↗