1.3x MXFP8 MoE Training Speedup vs BF16
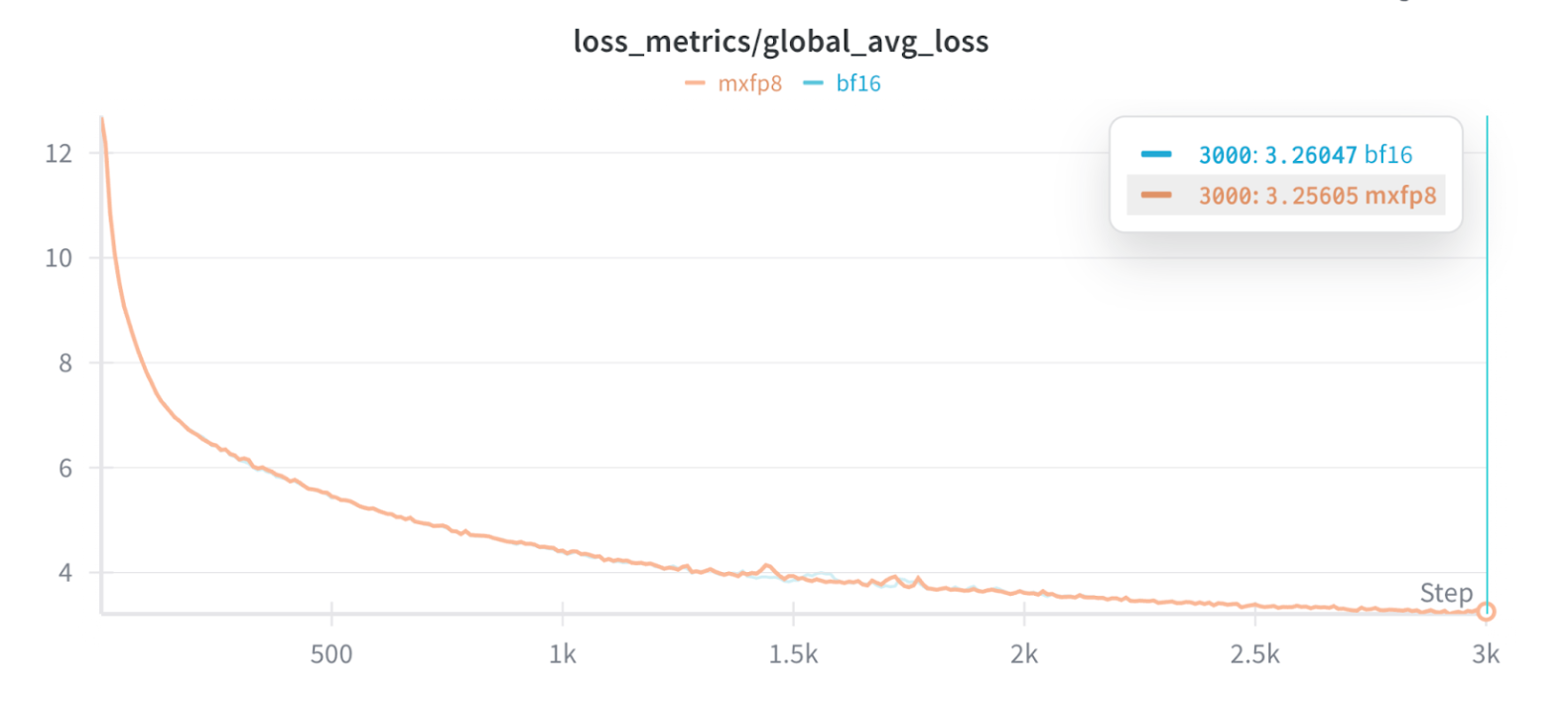
💡1.3x faster MoE training on GB200 w/ TorchAO – same convergence as BF16.
⚡ 30-Second TL;DR
What Changed
1.3x training speedup vs BF16 for Llama4 Scout
Why It Matters
Enables faster, cost-effective training of large MoE models on Nvidia GB200 hardware. Critical for researchers scaling LLMs efficiently without accuracy loss. Boosts PyTorch ecosystem for high-performance AI training.
What To Do Next
Integrate TorchAO MXFP8 primitives into your MoE training script on GB200 for 1.3x speedup.
🧠 Deep Insight
Web-grounded analysis with 5 cited sources.
🔑 Enhanced Key Takeaways
- •MXFP8 (mixed-precision FP8) represents an evolution beyond standard FP8, with dual datatypes (E4M3 and E5M2) and scaling factors that enable more efficient hardware utilization on NVIDIA Hopper and Blackwell architectures compared to BF16, while maintaining convergence parity[4].
- •FP8 training on NVIDIA H100 GPUs achieves throughput improvements from 415 TFLOPS (BF16) to 570 TFLOPS maximum, though this requires careful tuning of scaling policies and hyperparameters to avoid training instability and loss spikes[1].
- •The GB200 cluster represents NVIDIA's latest generation hardware (Blackwell architecture), which includes optimized MXFP8 support through dedicated Tensor Cores and NVIDIA Transformer Engine, enabling the reported 1.3x speedup for mixture-of-experts models[4].
- •TorchAO (PyTorch Automatic Optimization) integration of MXFP8 primitives demonstrates that lower-precision training can achieve 81% of theoretical peak performance while maintaining model accuracy, addressing earlier concerns about FP8 training stability in large-scale deployments[1][4].
🛠️ Technical Deep Dive
- •MXFP8 dual-datatype approach: E4M3 format (4-bit exponent, 3-bit mantissa) provides range up to ±448 for weight/activation quantization; E5M2 format (5-bit exponent, 2-bit mantissa) provides range up to ±57,344 for gradient scaling[4]
- •Scaling factor mechanism: Unlike BF16's fixed 8-bit exponent, MXFP8 employs dynamic scaling factors to represent weight, activation, and gradient distributions without requiring manual scaling adjustments[4]
- •Hardware acceleration: NVIDIA Transformer Engine (Ada/Hopper) and MXFP8 support in Blackwell automatically handle FP8 quantization/dequantization with minimal degradation, enabling transparent mixed-precision execution[4]
- •Training hyperparameter tuning for stability: Successful FP8 training requires careful configuration of gradient clipping (1.0), learning rate scheduling (cosine decay with warmup), and batch size (1024+) to prevent loss spikes observed in naive FP8 implementations[1]
- •Mixture-of-experts optimization: MoE architectures benefit disproportionately from FP8 due to reduced memory bandwidth for expert routing and activation sparsity, enabling the 1.3x speedup on GB200 clusters[1]
🔮 Future ImplicationsAI analysis grounded in cited sources
⏳ Timeline
📎 Sources (5)
Factual claims are grounded in the sources below. Forward-looking analysis is AI-generated interpretation.
Weekly AI Recap
Read this week's curated digest of top AI events →
👉Related Updates
AI-curated news aggregator. All content rights belong to original publishers.
Original source: PyTorch Blog ↗